[Review] 대규모 언어 모델(LLM)에 대해 알아야 할 8가지
오늘 리뷰할 내용은 Samuel R. Bowman의 'Eight Things to Know about Large Language Models'. 4월 2일에 나온 일주일된 내용이다.
Eight Things to Know about Large Language Models
The widespread public deployment of large language models (LLMs) in recent months has prompted a wave of new attention and engagement from advocates, policymakers, and scholars from many fields. This attention is a timely response to the many urgent questi
arxiv.org
저자가 인류학도인만큼, 기술적인 부분보다는 LLM이 가진 특성과 한계에 대해 인문학적 시각으로 접근하고 있다. 저자가 앞세운 8가지는 아래와 같다.
1. LLM은 목표한 혁신 없이도 지속적인 투자를 통해 더 많은 역량을 확보할 수 있음
2. 많은 LLM 행동은 부산물로써 예측할 수 없이 생겨남
3. LLM은 외부 세계를 학습하고 사용하는 것으로 보임
4. LLM의 동작을 제어하는 신뢰가능한 기술은 아직 없음
5. 전문가들은 아직 LLM의 내부 작동 원리를 해석할 수 없음
6. LLM은 사람을 뛰어넘을 수 있음
7. LLM은 제작자의 값이나 웹 텍스트에 인코딩 된 값을 표현할 필요가 없음
8. LLM은 프롬프트에 예민함
이 중, 몇 가지에 대해 자세히 다뤄보겠다.
1. LLM은 목표한 혁신 없이도 지속적인 투자를 통해 더 많은 역량을 확보할 수 있음

스케일링 법칙은 입력 데이터의 양, 모델 크기 (파라미터 개수), 연산량(FLOP으로 측정) 세 가지 차원에 따라 모델을 확장할 때 미래 모델의 성능이 얼마나 향상될 지에 대해 예측할 수 있다.
LLM 성능의 한 측정값에 대한 스케일링 법칙 결과, 모델 학습에 사용되는 계산량이 작은 프로토타입 시스템에서부터 GPT-4로 100억배 확장될 때 동안 일관된 추세를 갖는 것을 볼 수 있다.
2. 많은 LLM 행동은 부산물로써 예측할 수 없이 생겨남
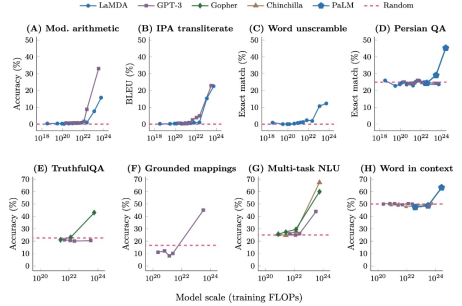
스케일링 법칙은 일반적으로 '불완전한 텍스트가 어떻게 계속될 지 정확하게 예측하는 모델의 능력'을 측정한다. 특정 작업에서 지속적으로 실패할 수는 있지만, 몇 배 규모의 동일한 방식으로 훈련된 새로운 모델은 잘 수행할 수 있다. 최신 LLM 구축에 들어가는 데이터와 컴퓨팅 시간의 대부분은 사전 학습 과정에 사용된다. 이 사전 학습은 자동 완성 작업과 유사하다고 생각하면 된다. 인공 신경망 모델이 텍스트를 한 번에 한 단어씩 받아 다음에 나올 단어를 확률적으로 예측하고, 향후 유사한 문맥에서 실제 다음 단어에 더 높은 확률을 할당하도록 동작을 점진적으로 조정한다. 사전 학습 테스트 손실은(스케일링 법칙에서) 이러한 예측을 얼마나 효과적으로 학습했는 지를 측정한다.
따라서, 새로운 LLM 훈련에 투자하는 것은 '미스터리 박스'를 구매하는 것과 같으며, 이는 새 기능을 얻을 수 있을거라고 확신하면서도 그 기능이 무엇인지 모른다는 뜻이다.
예를 들어, GPT-3가 기존 LLM과 다른 점은
1) 단 한번의 상호작용으로 소수의 예제를 통해 새로운 작업을 학습하는 능력인 소수점 학습과
2) 그 추론을 작성하고 그 결과 더 나은 성능을 보여주는 능력인 연쇄 추론을 보여준다는 것
이다.
3. LLM은 외부 세계를 학습하고 사용하는 것으로 보임
LLM이 세계에 대한 내부적 표현을 발달시키고, 이러한 표현을 통해 추상화 수준에서 추론할 수 있따는 증거가 점점 많아진다. 현재 LLM은 이런 기능을 산발적으로 수행하는 듯 보이지만, 시스템이 더 확장됨에 따라 더 강력해질 것으로 기대할 수 있다.
- 색상 단어에 대한 모델의 내부 표현은 인간의 색상 인식에 대한 객관적인 사실과 밀접하게 반영됨
- 모델은 문서 작성자가 알고있거나 믿는 것에 대해 추론하고, 이러한 추론을 바탕으로 문서를 작성함

위 그림은 시각 정보에 대한 접근 없이 훈련된 GPT-4의 비공개 버전이 그래픽 프로그래밍 언어로 유니콘을 그리는 명령어를 작성하도록 요청받아 진행된 결과물이다.
4. LLM의 동작을 제어하는 신뢰가능한 기술은 아직 없음
LLM 개발 비용의 대부분은 모델 사전 훈련에 투입된다. 사람이 작성한 텍스트의 무작위 샘플이 어떻게 계속 이어질 지 예측하기 위해 신경망을 훈련하는 과정이다. 연속 예측 이외의 다른 작업을 수행하기 위해서는 시스템을 조정해야한다. 특정 작업에 특화되지 않은 범용 지침 추종 모델을 구축하는 경우에도 이러한 종류의 적응이 필요하다. 모델은 인간에게는 모호해 보이는 상황을 포함하여 모호한 프롬프트나 인센티브를 불합리한 방식으로 잘못해석하여 예기치 않은 행동을 할 수 있다. 이 문제를 해결하기 위해서, LLM이 인간의 언어와 인간의 개념을 더 잘 사용할 수 있게 하는 것이다. 다만 사이코펀시 문제가 생길 수 있다.
사이코펀시는 모델이 사용자의 신념에 아첨하는 것으로, 사용자가 교육 수준이 낮은 것처럼 보일 때 모델이 잘못된 정보를 지지할 가능성이 높은 '샌드배깅'의 형태로 드러나는 것이다.